Training deep learning models can feel like trying to balance a stack of dominoes—one small misstep, and everything collapses. Neural networks are powerful, but they struggle with instability, slow convergence, and unpredictable learning behavior. This is where Batch Normalization comes in. It acts like a stabilizer, smoothing out the learning process and helping models train faster with fewer hiccups.
Normalizing activations at every layer keeps wild fluctuations at bay that might crash training. This elegant yet subtle hack transformed deep learning into an easier game of constructing stable AI models without futile adjusting. But how does it actually work?
Understanding Batch Normalization
Batch Normalization, often abbreviated as BatchNorm, is a normalization technique used on activations within a neural network. BatchNorm will modify the activation distribution per layer to stop drastic values from destabilizing the training. By reducing vanishing and exploding gradients that happen while training deep networks, normalization happens.
Simply put, Batch Normalization keeps each layer's inputs in a computationally manageable range. This is done by normalizing the activations by the mean and variance of the batch data being processed. After normalization, the values are scaled with learnable parameters, and the network is able to learn the fine-tuned normalized activations during training.
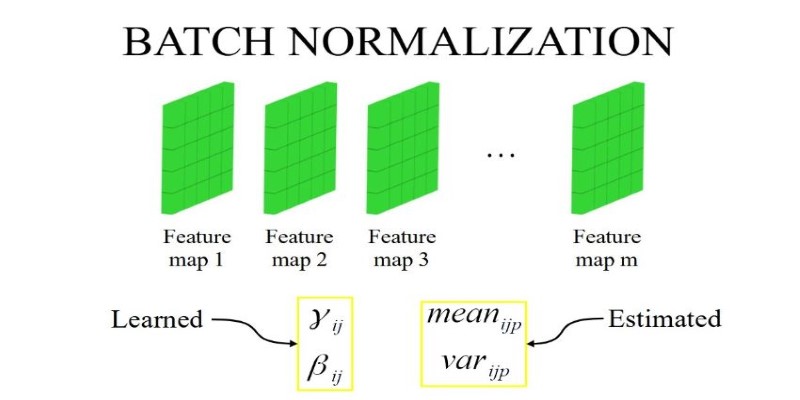
The Batch Normalization formula entails calculating the mean and variance for every feature within a batch. The activations are normalized by dividing by the standard deviation and subtracting the mean. To provide flexibility, two trainable parameters—gamma (γ) and beta (β)—are added so that the model can shift and scale the normalized values if required.
Why Batch Normalization is Important?
One of the largest hurdles in training deep learning models is managing the flow of activations between layers. Activations, if not normalized, tend to grow too large or become too small, causing slow learning or even the complete inability to train. Batch Normalization solves this problem in several key ways:
First, it improves training speed. By keeping activations within a stable range, models require fewer training epochs to converge. This means neural networks can learn faster without compromising accuracy.
Second, it helps with gradient flow. Deep networks suffer from gradients that either explode (becoming too large) or vanish (becoming too small). By normalizing activations, BatchNorm ensures that gradients remain in a useful range, preventing the network from getting stuck during training.
Third, it reduces sensitivity to weight initialization. In traditional training, poor initialization can slow down learning. Batch Normalization minimizes this dependency, allowing for higher learning rates without destabilizing the model. This means less manual tuning of hyperparameters, making the training process more efficient.
Finally, it acts as a form of regularization. Normalization introduces a slight noise effect, similar to dropout, which reduces overfitting. Although it doesn’t replace traditional regularization techniques, it complements them by making models more generalizable to new data.
How Batch Normalization Works in Practice?
Batch Normalization is implemented differently depending on the type of neural network, ensuring stable activations and improved training efficiency across various architectures.
Feedforward Neural Networks
In standard feedforward networks, Batch Normalization is typically applied to the activations of each hidden layer before the activation function. This ensures that activations remain within a stable range, preventing extreme values from disrupting learning. By normalizing layer inputs, the model achieves faster convergence and reduced sensitivity to weight initialization.
Convolutional Neural Networks (CNNs)
In CNNs, Batch Normalization is applied to feature maps rather than individual neurons. Instead of computing statistics for each neuron independently, normalization occurs across entire channels. This ensures consistent behavior across different spatial locations in an image, which is essential for stable feature extraction. Since CNNs process image data hierarchically, Batch Normalization plays a key role in preventing unstable feature distributions that could hinder learning.
Recurrent Neural Networks (RNNs)
Due to their sequential nature, Applying Batch Normalization to RNNs is more complex. Since these networks process time-dependent data, normalizing activations across time steps can introduce inconsistencies. This can disrupt the learning process, making Batch Normalization less effective for tasks like language modeling or speech recognition. As a result, alternative methods, such as Layer Normalization, are often preferred for stabilizing activations in sequential models.
Limitations of Batch Normalization
While Batch Normalization improves training stability and speed, it is not a perfect solution and comes with certain drawbacks.
Dependence on Batch Size
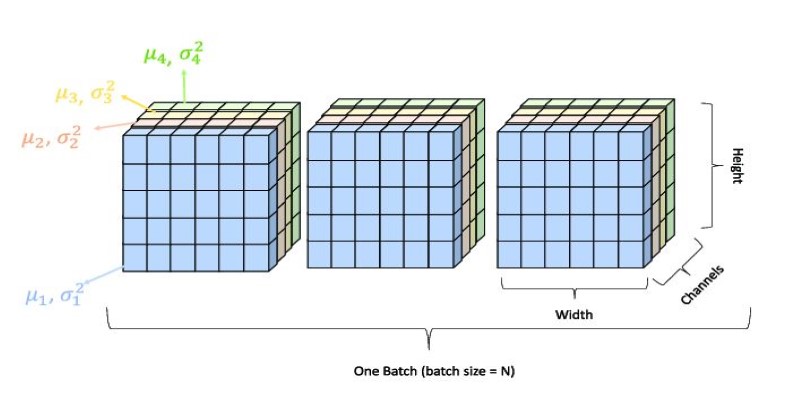
Batch Normalization relies on batch statistics to normalize activations, which means its effectiveness depends on having sufficiently large batch sizes. When using small batches, the computed mean and variance can become unstable, leading to noisy estimates that negatively impact training. This is especially problematic when working with limited datasets or training models on hardware that cannot accommodate large batches.
Challenges During Inference
During training, Batch Normalization adjusts activations based on the statistics of each batch. However, at inference time, the model cannot depend on batch statistics since predictions are often made on single inputs or smaller batches. Instead, it uses running averages collected during training. If these averages are not well-calibrated, the model may behave differently during inference, leading to inconsistent results.
Increased Computational Overhead
While Batch Normalization speeds up convergence, it adds extra computations to each layer. This overhead is negligible in large-scale models running on powerful GPUs, but it can be a concern in resource-constrained environments. Real-time applications, edge devices, and mobile deployments may struggle with the additional operations, making alternative normalization techniques more attractive.
Conclusion
Batch Normalization has transformed deep learning by improving training speed, stability, and efficiency. Normalizing activations across layers prevents vanishing gradients and slow convergence, making neural networks more reliable. Despite some limitations, it remains a widely used technique, reducing sensitivity to weight initialization and enhancing model regularization. While alternatives exist, BatchNorm remains a go-to method for stabilizing training dynamics. In deep learning, efficiency and stability are crucial. Without Batch Normalization, training would be far more complex, making this technique a game-changer for AI model performance.











